晨、秋、锦三人从院楼里出来,冬日和煦的阳光撒在每个人的脸上。时间是十三日的上午九点多。秋拖着行李,说着要去找她的自行车。三人因此草草分别,在这个可能是他们三个人生中最后一起碰面的上午。
神之转折
早上晨起晚了,到了院楼,看见了秋和她的行李箱。
锦还没来。他还在理行李。
三人决定睡在院楼,因为宿舍隔天早上八点就关门了,不能保证到时候就能起来。因此,理好行李在院楼睡上一晚,第二天早上结束后就能顺利去赶火车了。
做了一个上午的徒劳工作,每个人都没什么信心。最关键的是写手对于模型得有信心,不然越写信心越低,就越写不下去。
三人试着观察了一下各个州的新兴能源的分布比例:
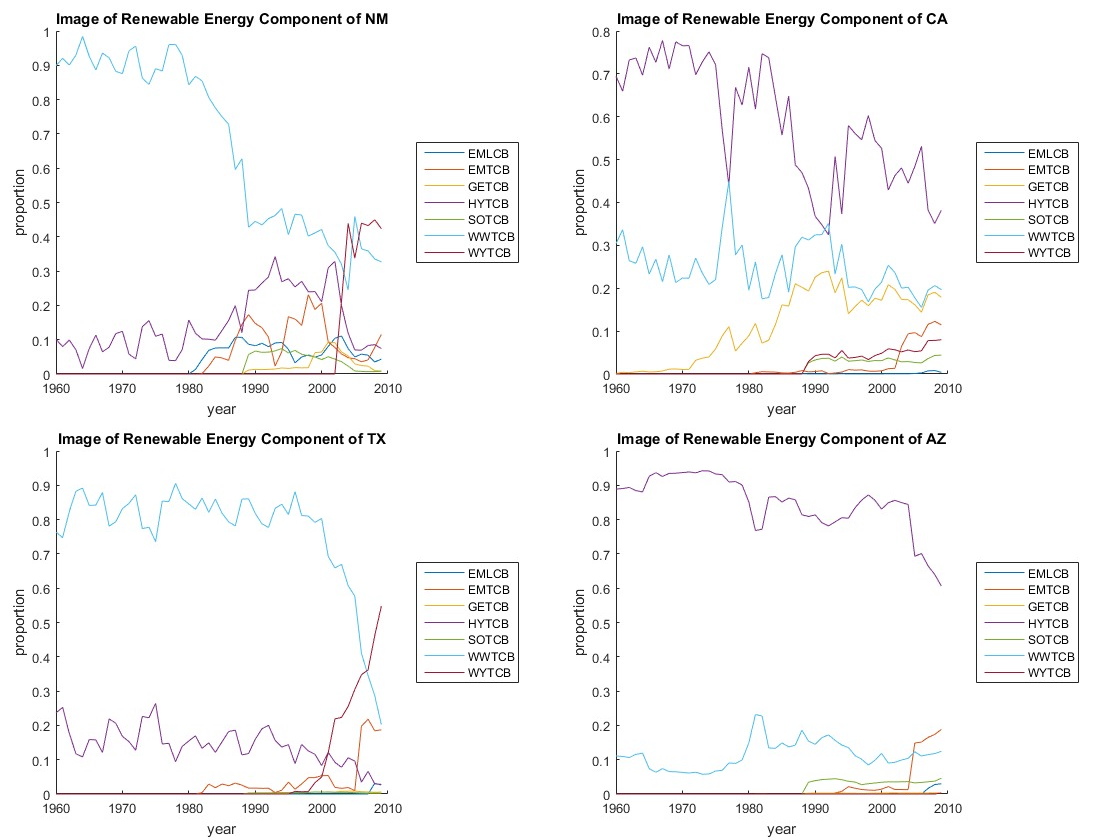
发现其中两个州(CA&AZ)一直是水电为主的新型能源;而其他两个州以往都是在用木头、最近开始使用风能。
那么思路来了:能不能看看CA和AZ的水电和新型能源总消耗量之间的关系?
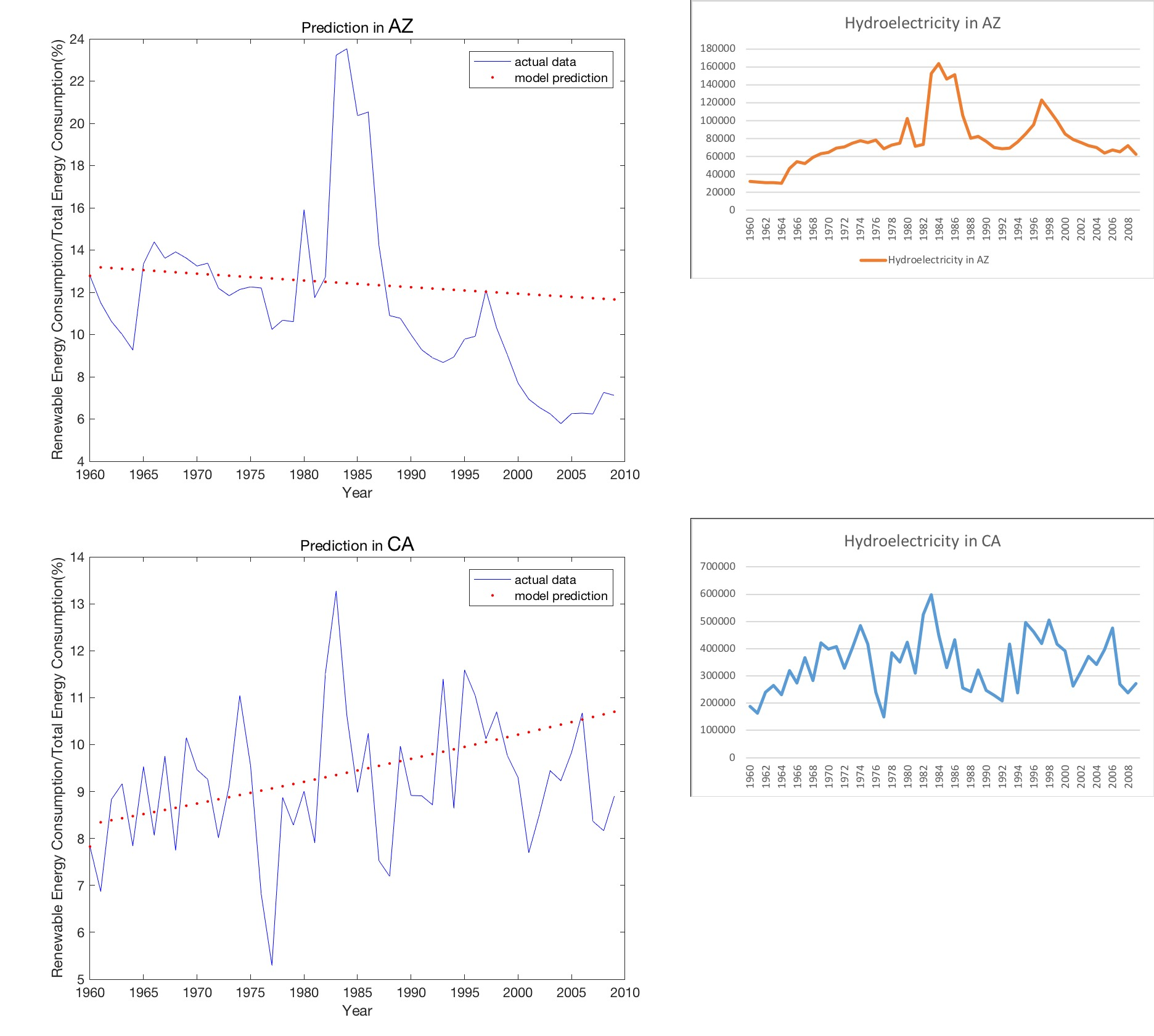
完美!水电连年的产量正与CA和AZ连年新能源产量的变化一致。
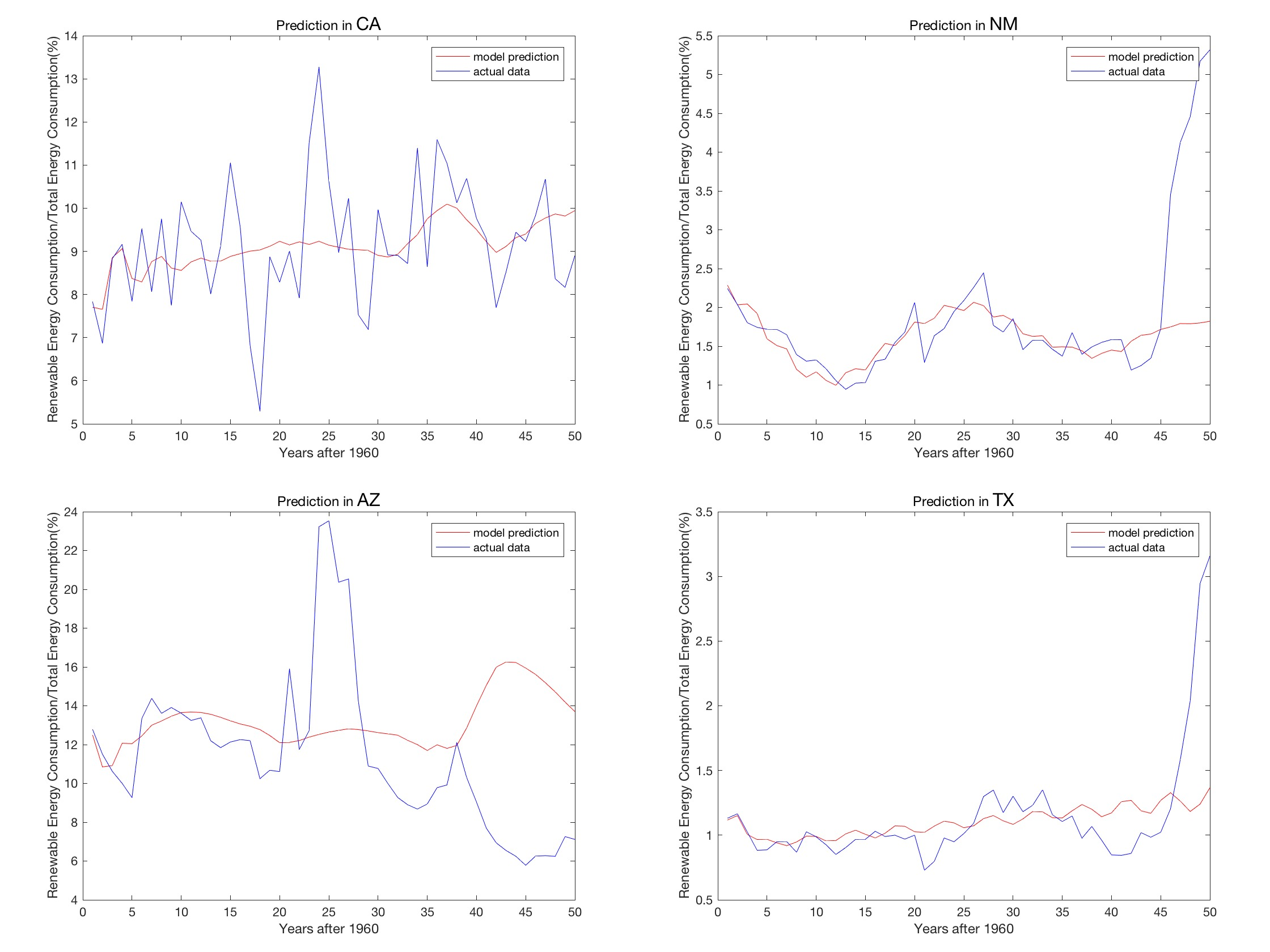
此外,研究NM与TX的风能,能够发现风能近年呈断崖式的上升。晨觉得可以考虑用逻辑斯蒂方程拟合。
于是推翻了之前的拟合方式(灰度预测,如下图),
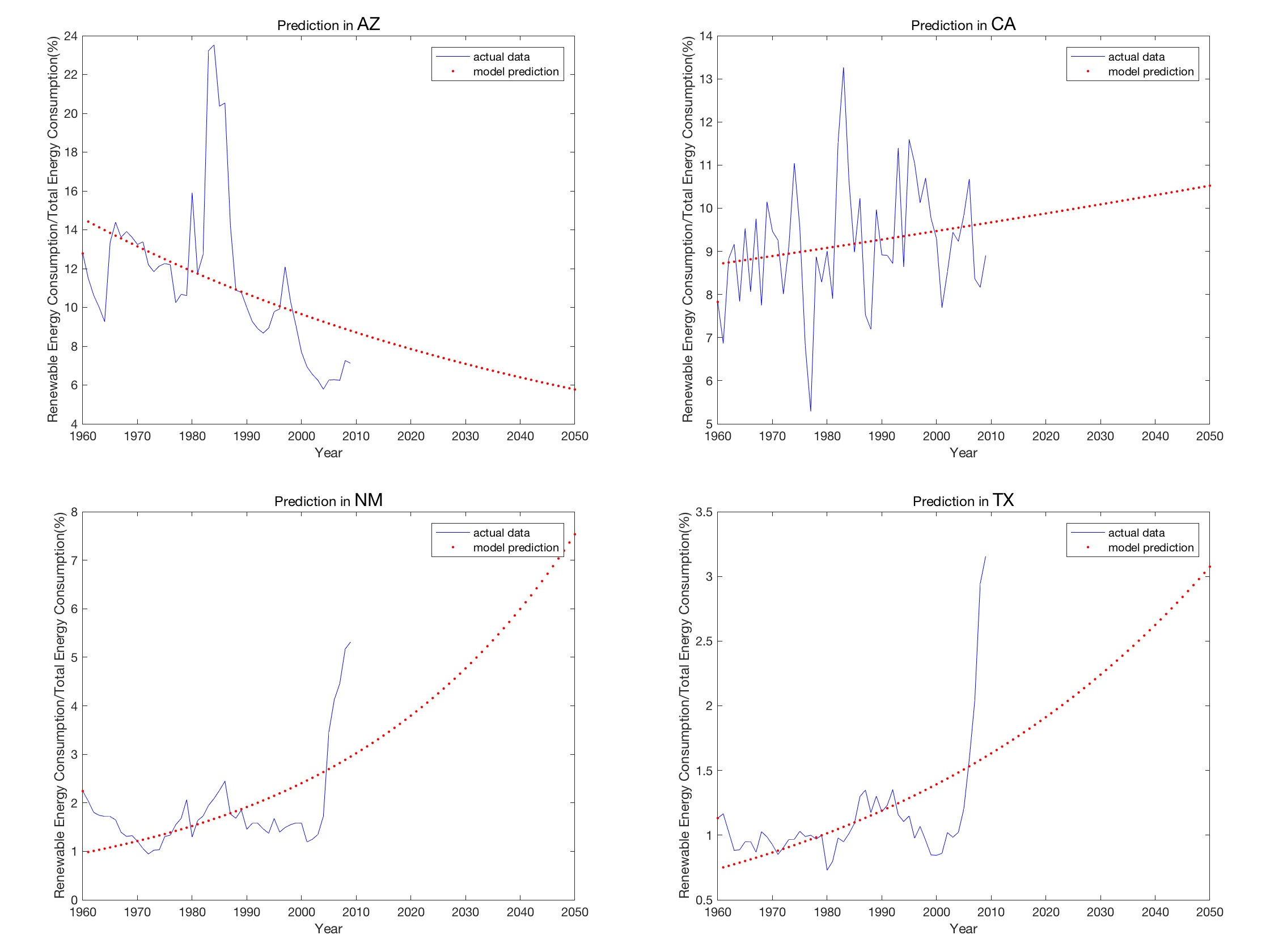
使用了logistic方程+sin函数(sin函数代表水电的变化,考虑到水电和降雨量息息相关,模型假设连年降雨量呈周期性的变化 >v< )的方法:
$E=c_1+c_2 \frac{1}{1+e^{c_3-t}} + c_4 \sin(c_5\cdot t+c_6)$
其中:
- $E$代表某州可再生能源的消耗量
- $c_1$是参量
- $c_2$是新生技术的最高上涨幅度
- $c_3$是新生技术突破时间点
- $c_4$是水电的最高上涨幅度
- $c_5$代表水电的波动周期
- $c_6$代表水电的初始值
这个公式背后的逻辑是:
- 水电的消耗量能够用sin函数来表示。因为消耗量与降水量正相关,而我们又假设降水量呈周期性变化。
- 新型能源的增长趋势能够用logistic函数来表示。因为新型能源在突破某个技术瓶颈后会被大量使用,上升极快。而使用到一定程度后便不再发展迅速,维持在一个稳定的被使用的数量。
Q: 模型是建完了,这些参数怎么定呢?
A: 拟合啊!
晨是实在懒得写梯度下降了,且感觉要一次性训练6个属性,此外还不知道这些属性的取值范围,根据之前的经验(大雾),分分钟要陷入局部最优解…… 于是晨使用了matlab的lsqcurvefit!
在无数次的调初始下降起点后,效果十分地好(至少比之前的好多了(痛哭))!
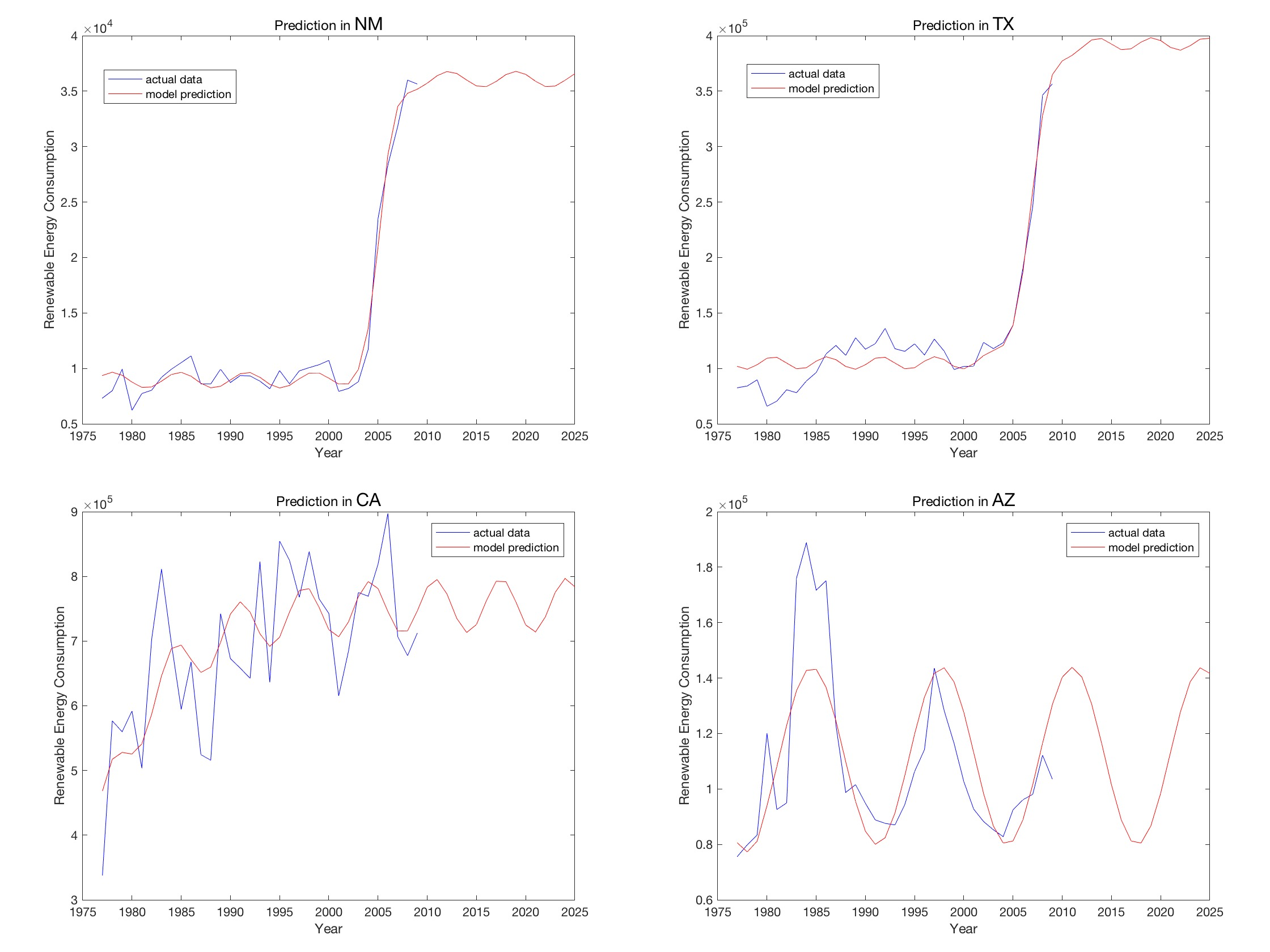
如此令人惊叹且简单的模型居然就出自三人之手,且再也不用在论文中提及那说不清道不明的ARMA,简直是神之转折。
比赛还剩下12小时。晨卖力地虐待着键盘。锦大力地虐待着键盘。秋暴力地虐待着键盘。突然秋说:“这些线条好像拉面!”
比赛还剩下八个小时,锦有点困,一头倒在了书桌上。秋飞快地写着latex。晨做着敏感度分析和summary。
比赛还剩下四个小时。晨也已经倒在书桌上了。秋觉得自己快睡了一个小时了,于是醒了过来。她发现自己只睡了四十几分钟。锦开始起来写晨没写完的summary。
比赛还剩下四十分钟。晨和锦从食堂买了肉包子和菜包子回来。锦和秋一起紧张地改着论文,两个人的脸色就像即将难产的孕妇。
在发送邮件的按钮被敲下后,比赛结束了。
讨论,讨论,讨论
秋在网上发现一篇讲灰色关联聚类的论文。这个技术也能够将大量的属性降维成少数保留原有意义的属性。过程简单来说如下:检查属性与属性之间的关联度,如果关联度达到一定程度就在这对属性之间建一对边,最后进行聚类。
然而correlation clustering是一个NP问题,因此晨只好使用了近似算法。算出了六个类。在这些类中分别取一个属性来代表他们类中的其他属性,也就做完了第一题。
最坑的是第二题。
晨一开始打算用ARMA来拟合第二题的数据变化,结果如下:
是不是很差劲?ARMA的假设是未来的序列能够通过过去的有规律的变化重复交叠形成。但是这个变化根本没有规律嘛……
接着秋找到了一份也是预测未来能源结构的论文,使用的是马尔科夫转移矩阵。但是晨否定了。晨觉得使用马尔科夫转移矩阵到最后,要么是能源结构恒定不变,要么是有规律地变化,绝不可能像上图这样的变化。
无可奈何,只能使用灰度预测。结果如下,但好歹100年后的百分比是正的……:
(灰度预测的预测结果)
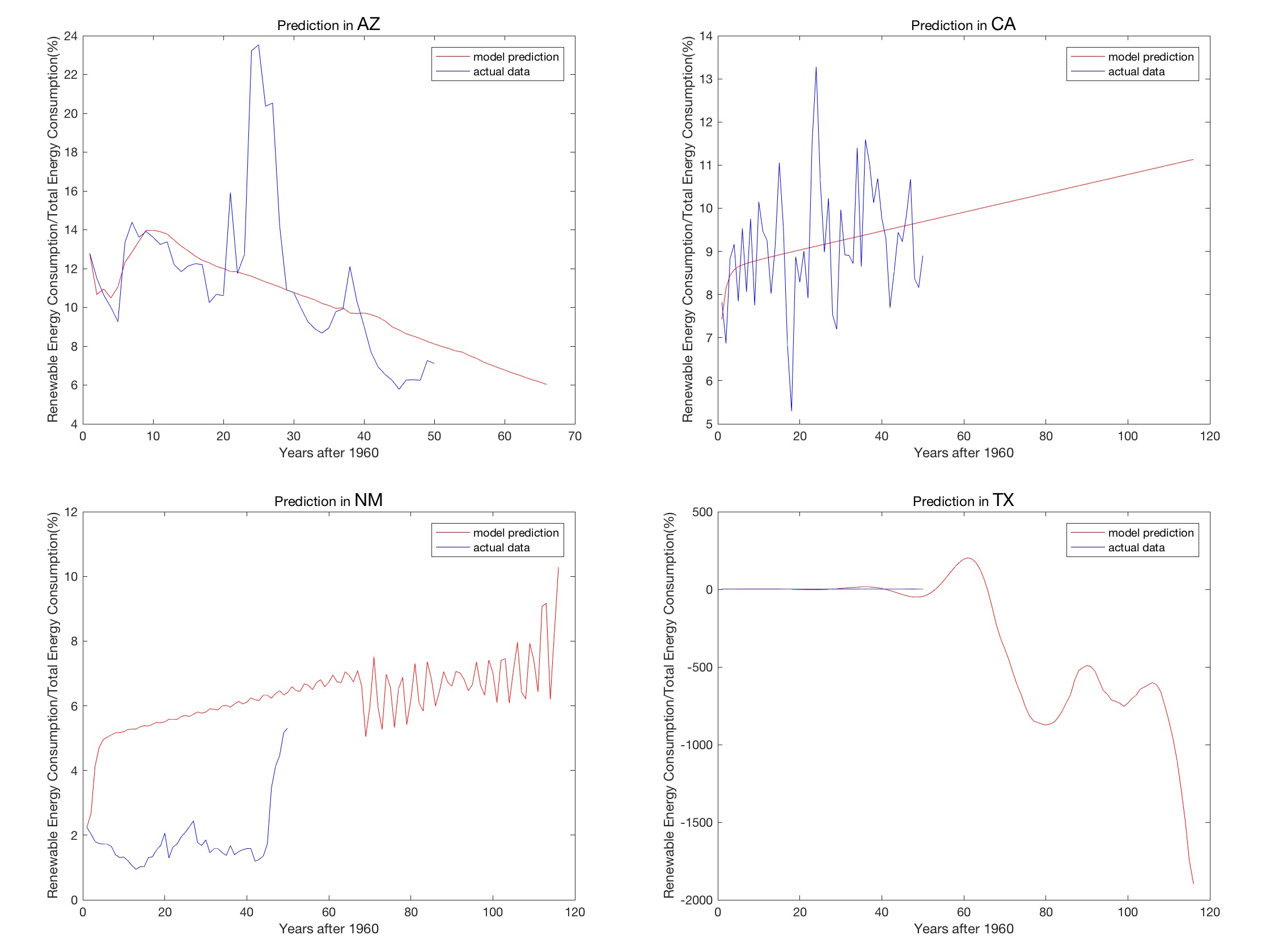
(ARMA的预测结果)
灰度预测看起来很像是指数函数。其实灰度预测GM(1,1)有一个前提,就是它的拟合的数据要呈指数式的上升。不管怎么看,这四个玩意儿都不像是指数函数嘛……
此外,三人使用ARMA和灰度预测还有一个致命的弱点:没有创意,都是现有的函数。
三人在预测上面消耗了两天的时间。因此比赛仅剩下了一天。
数据的玄学与美学
细看C题的要求,前三题这么讲道:
为四个州简述它们的能源使用概况。
建立模型,用来解释这四个州的能源概况在1960-2009年间是如何进行改变的。并使用模型以帮助这些州的州长们理解州之间的能源使用的不同与相似。
决定哪个州政府在2009年的能源使用情况最好。
三人先做第一题。既然每个州有六百多个属性、1960到2009年的数据能表达他们的能源使用概况,就有必要选取主要的属性来表达特征。
三人第一个想法就是使用PCA(主成分分析)。但是PCA的问题是:不能形象地解释每个降维后的主成分的现实含义。三人决定使用PCA,但是只选取使用占PCA后的降维转移向量的分量的较大的属性作为能代表整个属性集的属性。
等三人做完PCA,研究每个转移向量的时候,问题出现了:权重较大的属性很多,或者说没有哪个属性是权重较大的。
三人懵逼了很久,决定先看一下数据,发现了数据中有许多套路。于是三人制订了一下数据清理的规则:
- 删掉描述相同、但是计量单位不同的属性,因为这两个值之间可以相互线性转换。
- 在price和consumption都存在的情况下,删掉了expenditure(它们之间存在线性关系)
- 删掉了包含end-use的项,因为三人考虑的只是整个州的能源概况,而不需要考虑其中末端的使用。
- 删掉泛化到United States的数据(因为三人只需要考虑仅与州相关的数据)
- 三人观察到industrial, commercial, transportation,的价格和average in total的是差不多的,于是只留下了average in total的数据。
- 删掉’Factor for…’,因为它是一个常量,和物质本身的属性有关。
- 删掉在1960年之后含有为0的属性,因为它会影响模型分析的准确度。
- 删掉包含residential、Coke plant和electrical sector的信息,因为这些都是极其specific的信息,与整体的能源使用情况没有多大的关联程度。
- ’Total energy used as process fuel’删掉,因为每个州处理能源的方式都一样,因此每个州的处理能源消耗的能量和消耗的总能量的比例都是差不多的。
等删掉这些数据,一共只剩下56个属性了。做了一次PCA,每一个属性的权重都差不多。咋办,要一一写上去吗?
选题
晨六点半一醒来,发现题目已经出了:
A题:无线电会在电离层上反射,再在海平面上反射,再在电离层上反射,再在海平面上反射……求其反射的规律,并考虑海平面的波动。
B题:地球上大概有6900种语言。求这些语言使用者的散布(distribution)规律。
C题:我这里有六百多个属性能表达各州使用新兴能源的方式。挑出你觉得重要的属性,并预测它们未来的变化。
D题:在韩国、或者爱尔兰、或者乌拉圭,全国内建下无人车的充电站吧。告诉我们每个充电站的位置。
E题:气候变化是怎样让政府变得无能的?
F题:晨没看,因为题目有8个Task。
晨的第一个反应就是F题不做,因为题目太多了,每一次回顾看的时候都要花很多时间。第二个反应是A题不能做,因为无线电是物理或者电子的专长,而队伍中并没有擅长这些。第三个反应是E题不能做,因为“无能”这个含义太抽象了。
等锦带着包子过来后,三人讨论,决定在BCD中选题。三人分别在纸上写出他们中意的两道题。他们把各自的答案展示出来,发现结果分别是BC, CD, DB。
没办法,只好一一细细看。B题要讨论哪些因素决定了这些语言使用者的散布,但光是题目中列着的因素就有international business relations, increased global tourism, the use of electronic communication and social media, and the use of technology, the language(s) used and/or promoted by the government in a country, the language(s) used in schools, social pressures, migration and assimilation of cultural groups, and immigration and emigration with countries that speak other languages. 找数据可能十分困难。
C题是三人最终定的题,但一开始选的时候不知怎么漏了,没考虑。
D题的思路是仿照通信基站的扩张方式:使用蜂窝网覆盖全国,每个蜂窝网先配置一个充电站。如果单一个充电站满足不了该蜂窝网内的客户的需求(这里可以用模拟的方式来看有没有满足需求),就将对应的蜂窝分裂成若干个小蜂窝,每个小蜂窝配置一个充电站。
三人一开始决定做D题。吃过午饭后开始找数据。发现特斯拉的充电站的数据很难从网上扒下来,且他们建充电站的规律时:在城市建足够多的充电站,此外需要沿高速公路等距离地建充电站,以满足长途旅行者的需求。且三人发现公路的经纬度也难以从网上找到对应的数据。D题基本宣布放弃。
这时吴和秋发现迟迟没有讨论的C题:C题的数据是直接给定的,且C题的思路也很清晰:可以用PCA(主成分分析)降维,然后用灰色预测;或者建立微分方程、用回归定参数。
于是三人决定做C题。
准备
晨在六食要了份滑蛋饭,和锦对坐了下来。秋说她一会就到。过了会秋来了,穿着黄色的衣服。三人互相讨论了一些现在已经忘了的鬼话。
滑蛋饭有点咸。
到了院楼,他们去了105室。秋在QQ群里发了六道今年美赛建模的模拟题。三人看了好久的英文题目。晨感觉每一题都怪怪的:“A题问的太多了;B题看不懂;C题太简单;D题和E题可能要找很久数据;F题没思路……”然后三个人决定做关于火灾的题目。题目大致内容是:预测森林火灾的生长模式,并比较三种火灾的预警系统的性能。晨的第一个反应就是使用元胞自动机。之后不知道怎么,秋把出模拟题的QQ群给了晨和锦。过了一会儿,晨觉得这个群是忽悠群,因为里面那个出模拟题的老师说今年考机器学习的概率很大,然而往年并没有出机器学习的题目。
三人决定放弃模拟题,去做做真题。他们选了一道厄多斯(一个数学家)的题目:构造出厄多斯-1(指的是和厄多斯有直接论文合作的人,厄多斯-2指的是和厄多斯-1有直接论文合作的人,以此类推)作者们之间的合作网络,并决定他们之间谁最有影响力。
晨和秋都觉得这是使用PageRank的大好机会。三人研究了半天的PageRank。第一题做完。接下来的题这么说:构建一个论文和论文之间的引用网络,并指出哪个论文最有影响力。用相同的方法应用于如影星之间的、歌手之间的、记者间的、博主间的网络。三人就围绕这些题做了四天。
在围绕这些题的同时,秋换了一个Tex,安装了MCM模板。这个准备很关键,节省了三人在比赛中的安装tex的时间。晨看了五六篇O奖论文,写了模拟退火的模板。锦也看了论文,并写了遗传算法的模板。这些模板最后都没有用到。此外他们还找到了一个能互相传文件的免费平台,叫有道云协作。
雪菜肉丝面&菌菇肉丝面
比赛结束的中午,晨和锦决定去学则路蓝蓝路旁边的面馆吃饭。快到的时候,
锦突然问晨:“你带钱了吗?我没带手机。”
晨:“??” 他打开钱包看了看,只有二十几块。现在在东部城市二十几块钱下馆子能吃到啥啊……两人一边这么想一边朝面馆走着,想碰碰运气。
到了面馆,发现最低的面的价格居然只有十二块!!于是晨点了碗雪菜肉丝面,锦点了碗菌菇肉丝面。
在两人的肚皮鼓了之后,晨的钱包就瘪了。
感谢&总结
这可能是晨大学为数不多的团队合作经历了。
晨很感谢锦和秋能成为自己的队友。每次晨感觉很焦虑、很不安、很暴躁、很紧张的时候,听见锦和秋的话语,就感觉跑完1000米时有人给晨递水,很平静。他们也都是很幽默的人:当晨在想出逻辑斯蒂方程加正弦函数的方法之前,觉得模型太差了不能做、想要放弃,但秋说,大不了就把现有的方法写上去呗。晨觉得被鼓舞了。
晨总结了一下几点:
坚持就是胜利:不管结果多差,只要文章的步骤完整、思路清晰,就肯定有成功参与奖。坚持到底,就不辜负自己,也难得后悔。
对话的技巧:
讨论时,句子少包含“你”,多包含“我们”。晨觉得用“你”容易带来攻击性;而“我们”可以把双方的利益归一。
少包含指示性的词语。如“它们”“这个”“那个”“搞”“弄”,替代为完整的主谓宾。
事先准备
论文的模板。
模型的模板,或者多看看O奖。
晨觉得这次比赛真的是不错的经历,不仅是一次与团队的宝贵记忆,还让晨认识到了自己的沟通能力(讲话时挺结巴的)、代码能力(作为算手不如锦……)、时间规划能力(需要事先定好计划)。晨决定今后好好写代码,今年看完《沟通的艺术》。