由于Region Proposal是限制计算时间的瓶颈,而Selective Search在CPU实现下处理每张图片需要2秒的时间,产生了以下两个自然的想法:
能不能让Region Proposal在GPU上面跑?可以是可以,但是Selective Search与Detector仍然是相互消耗着计算和存储资源的,达不到一体化的方式。
使用某种GPU的方式替代Selective Search。这种方法很多,但都是在图片进入卷积之前进行的RP。有没有能利用卷积之后的Feature Map的信息的方法?
也就是说,我们想找一种模型,它的输入是Feature Map或者是Feature Map的一部分,它的输出是经过挑选的Region Proposal。最无脑的想法就是全连接层啦。
说是全连接层,具体要怎么做呢?首先问题可以简化为把Feature Map的一小部分作为输入,而不是全部作为输入。分类层可以只关注一小部分的信息来进行分类。这样做的原因是图片的需要识别的部分往往仅占整个图片的一小部分。另外一个简化是BBox精修层顺便可以根据这一小部分的信息把需要预测的窗口回归(精修)出来。由于这两者都是根据特定的窗口做信息的表示处理,且它们可以根据特征向量得出预测。因此可以把负责将一部分Feature Map变为Feature Vector的网络放在这两者的前面,这样就不仅达到了信息浓缩的目的,也简化了这两个层的大小。
RP网络的整个结构如下(摘自Faster RCNN 详解):
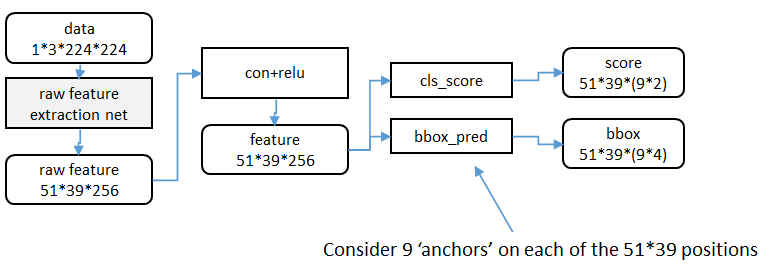
(这个图可能有错,错在score可能是51*39*(9*1),请读者也帮我判断一下)
新问题是,这个一小部分的信息占Feature Map的多少?有以下两种想法:
根据不同的对应点的的特征来定义以对应点为中心的窗口大小。好处是精度高,坏处是时间复杂度是接下来讲的第二种的n倍。
写死窗口大小。Faster R-CNN使用了3种规模的 x 3种比例的窗口(论文里写他们这个参数不是调出来的)。这样参数少,时间少。这些窗口叫做Anchor Box。
好的,我们可以理解上图中最底下那行字了:
Consider 9 ‘anchors’ on each of the 51*39 positions.
即,Feature Map大小为51*39,在Map的每个点上取9种Anchor Box,则一共得到51*39*9个Anchor Box。此后RPN还要负责检查每个Anchor Box是否是背景、以及帮助重新精调Anchor Box的大小。
你可能又要问了:为什么这里要检查是否是背景呢?直接塞给后面的Detector来检查不好吗?我也有这个疑惑。我现在的解释是先在这里检查是否是背景可以先删掉一些简单的可以判别不是待检测物体的Anchor Box,便于后面的网络学到更容易错的样例。(有一点Ensemble的意思)
另外一种解释在这整个Faster R-CNN的结构图里看出来:
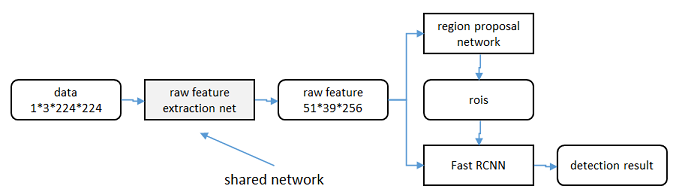
在RPN之后居然还经过了一层RoI Pooling,然后再给Fast R-CNN判别是哪一个类。为什么要经过一层RoI Pooling,直接把之前RPN得到的特征向量给另外一层FC来判别不好吗?
这就是Faster R-CNN比起Fast R-CNN聪明的地方:它重新利用了精调后得到的窗口,在此基础上重新生成特征向量,精度自然会提高。如果我们回想一下Fast R-CNN的结构,会发现Fast R-CNN的判别类的模块和精修窗口的模块是平行的:Classifier与Bounding Box Regressor获取到的都是根据SS的对应区域RoI之后得到的特征向量。因此在Fast R-CNN中,精修窗口模块得到的信息没有被网络重新利用。在Faster R-CNN中,这个信息被重新利用,判别类的模块的感受野得到了精修,精度得到了提高。
另一种看待RPN和CLS层的方式
原论文中有一句话很有趣:
Using the recently popular terminology of neural networks with ‘attention’ mechanisms, the RPN module tells the Fast R-CNN module where to look.
RPN层是这样的Attention机理。前面的CNN模块提供给它一系列的Anchor Box,RPN层通过学习学得哪些Anchor Box该看,哪些不该看,哪些该改一改视角看。
总结
文章的训练流程挺奇怪的。是4-Step Alternating Training,但是前面在谈两步交替训练与近似/非近似联合训练。希望如作者所说,是因为“实现问题与截稿日期”的原因才临时选取了这种方法。
总得来说,Faster R-CNN通过RPN获得了RP,并精修了BBox,然后通过Classifier获得类别和再精修。个人感觉已经基本榨干了两步走式网络的油水。
可以期待的改进:
- 把FC层去了。