FPN
下图出自FPN(feature pyramid networks)算法讲解:
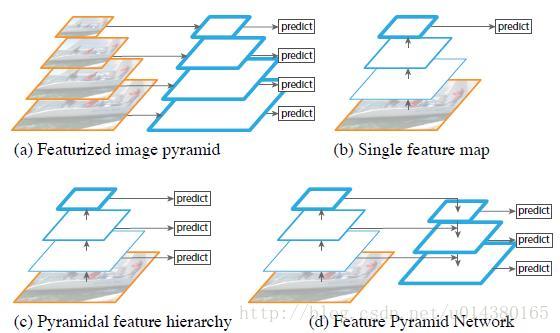
可以看到,FPN从多尺度的特征图上提取信息,并联合进行预测。
同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
简而言之,就是吸收了网络中各种层次的信息,避免了信息的丢失。
这和Attention是一个思路。
Mask
Mask意为掩码,即通过与目标数字的按位操作,达到屏蔽指定位的需求。
在Mask R-CNN中,Mask模块负责对ROI池化后的m x m的图进行掩码,得到的掩码即为对应的实例分割的对应区域。
具体怎么做?在m x m的图上进行全卷积即可。不用FC的原因是FC层包含实数,且FC易丢失对于每一个像素的具体信息(设想一下把矩阵镜像对称一下,然后把输入也镜像对称一下,结果是不变的)。
好的,这里我们就能看出,Mask对于RoI的要求是很高的,RoI不能丢失对于特征图的像素位置的精确信息,否则比如说一个像素被劈成两半再过RoI,它代表的位置的信息就不单单是那个像素位置上的像素本身的值了。它需要向离它较近的像素值靠拢,也就需要插值的手段。之前的的RoI池化做不到,因为之前的RoI的像素值直接取整。
这就促生了下一节的RoI Align。
Mask掩码有K个通道,针对每一个类都有一个通道。针对同一个类的FCN是在不同的RoI之间共享的。那么问题来了:为什么不做同一个通道,然后Softmax呢?
论文这么解释:
Mask R-CNN decouples mask and class prediction: as the existing box branch predicts the class label, we generate a mask for each class without competition among classes (by a per-pixel sig- moid and a binary loss). In Table 2b, we compare this to using a per-pixel softmax and a multinomial loss (as commonly used in FCN). This alternative couples the tasks of mask and class prediction, and results in a severe loss in mask AP (5.5 points). This suggests that once the instance has been classified as a whole (by the box branch), it is sufficient to predict a binary mask without concern for the categories, which makes the model easier to train.
通过将分类和掩码解耦,掩码已得到充分的训练信息,更加容易训练。个人认为原因是FCN善于处理将图片进行变换的问题,但FCN并不擅长于生成概率(即分类的概率),因为分类任务需要集中精力在高层抽象表示的不同特定区域,这是FCN做不到的。而且K个输出也足以表示对于不同的类进行不同的掩码,至于到底取哪一个掩码,就由FC来做吧。
ROI Align
前文已提到如下的考虑:
This pixel-to-pixel behavior requires our RoI features, which themselves are small feature maps, to be well aligned to faithfully preserve the explicit per-pixel spatial corre- spondence. This motivated us to develop the following RoIAlign layer that plays a key role in mask prediction.
因此Mask R-CNN使用了双线性插值,方法如下图:(图片来源:图像处理:五种插值法)

对于处于P位置斜对角的四个像素,根据P相对这四个像素的距离进行插值,从而得到P位置的精确的像素信息。(笔者认为这个插值方法还能进一步修改,比如八个位置一起插值2333)
通过这种精确得到RoI的方式,保留住了反向的对应的原图上的RP的像素大小,使得掩码操作较为精确。
总结
Mask R-CNN使用了简单的方法,以及很多的结构上的小创新。效果是无话可说的。其中我最喜欢的部分就是RoI Align,依我看来,这是对于池化有很深见解,且对图像处理方法很了解的人才能做出的创新。这表明基础还需要一步步打扎实才行。
可以创新的地方:
- 使用其他插值方法。