文章背景
现在的数据大多都是多模态的数据。这篇文章想要做的事情是:在根据给定的实例的情况下,以最少的计算,提取最少数量的模态,获得较准确的预测结果。
相关工作
| Method | Pros | Cons |
|---|---|---|
| dimension reduction | 计算量比起数据不降维时的要小 | 需要提取几乎所有种类的模态 |
| feature selection | 计算量少、所需模态少 | 粒度不够细,不能够针对不同的实例选取不同的feature集合 |
| cascade detection | 能选取不同的Feature集合 | 需要在大量缺失的Feature上运算 |
| cost-sensitive trees of classifiers | 能够针对不同的实例的已知Feature,选择不同的所需的Feature集合 | 只适用于Feature extraction,不适用于Modal extraction |
本文提出的方法能够在单个标签对应多个模态的组合的场景下,根据不同的实例的特征,选取不同的所需的模态,进行高效、快速的预测。
论文方法
论文使用了一种基于LSTM的方法。
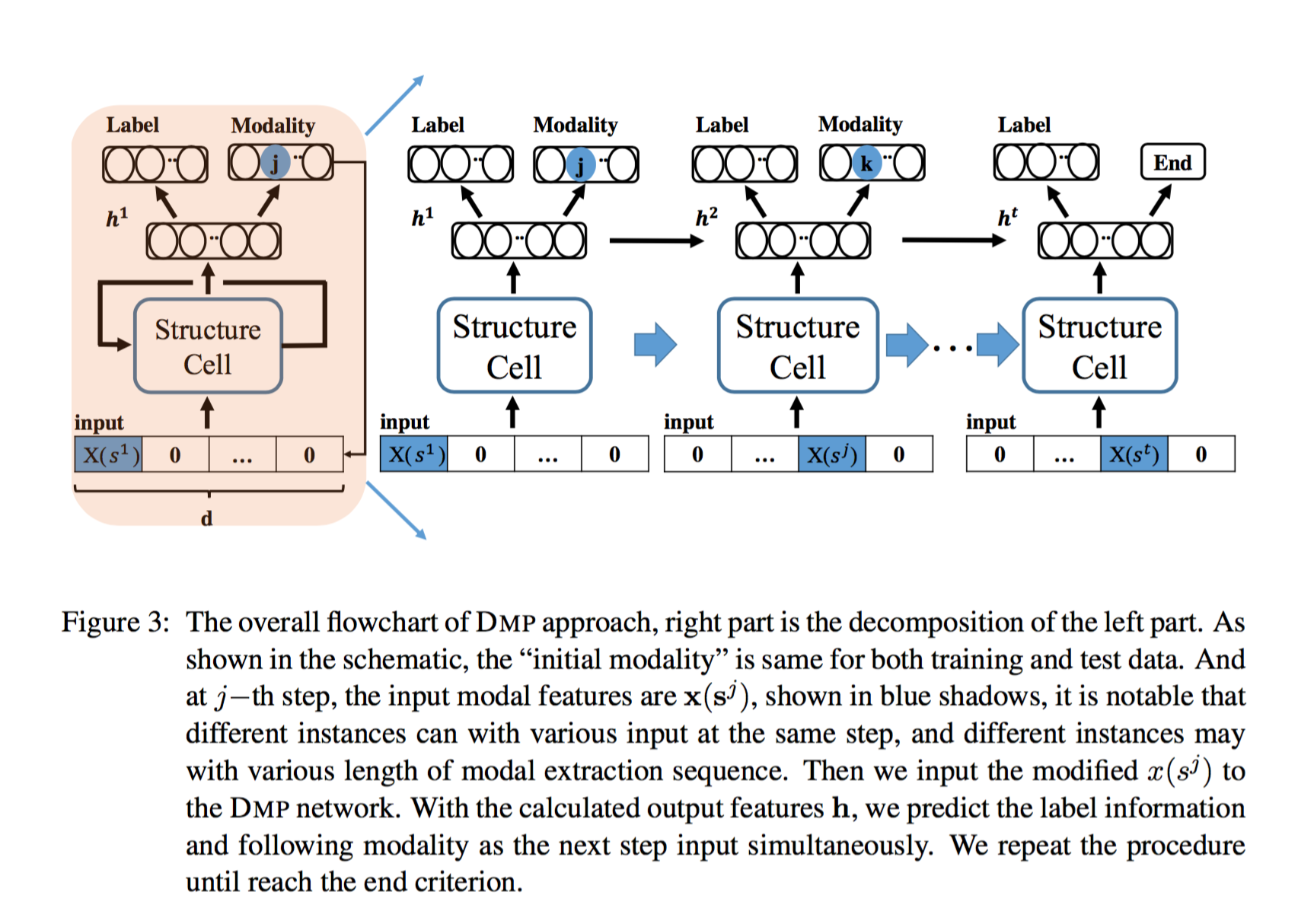
每一个循环时,LSTM接收一个只有一个模态有值,其余模态对应位置为0的输入,并生成隐状态/输出。
算法将该输出与之前LSTM的输出按生成的次序合并,合并后的矩阵喂给两个神经网络,一个神经网络负责预测标签的值,另外一个神经网络负责决定如果没有停止循环,那么下一次循环提取哪个模态。
该论文的改进方法
该论文方法清晰,手法巧妙,在各种规模的数据集上也达到了不错的效果。
我认为若改进以下的两个方面,可能能够使得Effectiveness与Efficiency能有进一步的提高:
缺陷:
进行决策与预测的两个神经网络的输入是变长的。论文使用的方法是在每一次循环的时候将之前的LSTM的所有输入堆叠,按照堆叠后的矩阵进行决策和预测。而由于LSTM要循环多少次是依Instance而变的,因此对于每一种经历了不同循环轮数的LSTM,都要训练一个对应于轮数的神经网络。这造成了计算上的浪费,以及数据集可能会较少导致欠拟合。
解决方法:
观察到LSTM是一个循环网络,其中LSTM的隐状态都或多或少地包含了之前所有的输入(模态)的信息。我觉得可以仅通过最近一次循环中,LSTM的隐状态进行预测和决策。由于单个隐状态的长度是固定的,因此仅需训练一对定长输入的神经网络,减少了计算的消耗、以及数据集被分割的风险。
局限:
在实际生活中,单个模态往往不只是一个实值,而是一个向量甚至是矩阵。论文中LSTM的输入是一个每个分量都有实际含义的向量,即:该论文只考虑了单个模态是一个实值的情况。
扩展方法:
将这些向量/矩阵按顺序拼接成一个很长的向量。当算法决定需要读入第n个模态时,将一个目标模态的对应的分量位置均为实际值,其余分量均为0的向量喂给LSTM。